5.1 데이터 무결성
손상된 데이터를 검출하는 일반적인 방법: 처음 유입되었을 때 & 신뢰할 수 없는 통신 채널로 전송되었을 때 체크섬 계산
단점: 원상복구하는 방법 제공 ❌, 에러 검출만 수행
5.1.1 HDFS의 데이터 무결성
i) 읽기 과정에서 블록 검증
데이터노드: (클라이언트 or 다른 데이터노드로부터) 수신한 데이터 검증
클라이언트: 데이터노드에 저장된 체크섬 & 수신된 데이터로부터 계산된 체크섬 검증
ii) 저장된 모든 블록 주기적으로 검증
DataBlockScanner: '비트 로트'에 의한 데이터 손실 피함
if 에러 검출)
클라이언트: 훼손된 블록 & 데이터노드 정보 ➡️ 네임노드 보고, ChecksumException 발생
네임노드: 복제본 손상 표시, 해당 블록 복사 금지, 해당 블록 다른 데이터노드에 복제되도록 스케줄링 ➡️ 블록의 복제 계수 원래 수준으로 복구, 손상된 복제본 삭제
체크섬 검증 비활성화
setVerifyChecksum() = false
5.1.2 LocalFileSystem
LocalFileSystem: 클라이언트 측 체크섬 수행
파일 시스템 클라이언트: 파일과 같은 위치의 디렉터리에 숨겨진 파일 .[파일이름].crc 내부적으로 생성 (청크: 512 Byte)
if 에러 검출) CheckSumException 발생
if 기존 파일시스템: 자체적으로 체크섬 지원) RawFileSystem 사용
5.1.3 ChecksumFileSystem
LocalFileSystem: ChecksumFileSystem 사용
5.2 압축
- 파일 압축: 파일 저장 공간을 줄임, 데이터 전송을 고속화
- 공간과 시간은 트레이드오프 관계: 압축과 해제가 빨라질수록 공간이 늘어남
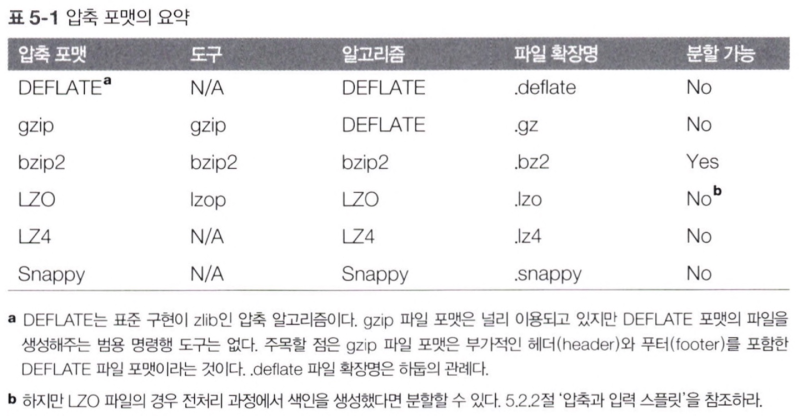
- gzip: 일반적인 목적의 압축 도구, 공간/시간 트레이드오프의 중앙에 위치
- bzip2: gzip보다 더 효율적으로 압축, 다른 포맷에 비해 느림
- LZO, LZ4, Snappy: 속도에 최적화, 압축 효율 떨어짐
- '분할 가능'열: 압축 포맷의 분할 지원 여부 -> 분할 가능하면 맵리듀스에 적합
5.2.1 코덱
- 코덱: 압축-해제 알고리즘을 구현한 것
- 하둡에서 코덱은 CompressionCodec 인터페이스로 구현됨

- LZO 라이브러리: 별도로 내려받아야 함
- LzopCodec: lzop 도구와 호환됨, 핵심적인 LZO 포맷에 부가적인 헤더가 포함된 것
- LzoCodec: 순수한 LZO 포맷
<CompressionCodec을 통한 압축 및 해제 스트림>
- CompressionCodec은 데이터를 쉽게 압축하거나 해제해주는 두 개의 메서드를 제공
- createOutputStream(OutputStreamout out): 압축되지 않은 데이터를 압축된 형태로 내부 스트림에 쓰는 CompressionOutputStream을 생성
- createInputStream(InputStreamout in): 입력 스트림으로부터 읽어 들인 데이터를 압축 해제, 기존 스트림으로부터 비압축 데이터를 읽을 수 있는 CompressionInputStream을 반환함

1. 애플리케이션의 첫 번째 명령행 인자는 CompressionCodec 패키지의 정규화된 전체 이름
2. 그 코덱의 새로운 인스턴스를 생성하기 위해 ReflectionUtils 사용, System.out의 압축 래퍼를 얻음
3. 입력을 출력으로 복사하기 위해 IOUtils의 copyByyes() 유틸리티 메서드를 호출, CompressionOutputStream으로 압축
4. 마지막으로 CompressionOutputStream의 finish() 호출, 압축 도구에 압축된 스트림 쓰기 중단을 요청하지만 스트림 자체를 닫지는 않음
<CompressionCodecFactory를 사용하여 CompressionCodec 유추하기>
- CompressionCodecFactory의 getCode() 메서드는 지정된 파일에 대한 Path 객체를 인자로 받아 파일 확장명에 맞는 CompressionCodec을 찾아줌


<원시 라이브러리>
- 성능 관점에서 압축과 해제를 위해 원시 라이브러리를 사용하는 것이 바람직함

- 하둡은 lib/native 디렉터리에 미리 빌드된 64비트 리눅스용 원시 압축 라이브러리를 제공
- 원시 라이브러리는 자바 시스템 속성에 따라 선택됨
- 기본적으로 하둡은 자신이 수행되는 플랫폼에 맞는 원시 라이브러리를 먼저 찾고, 있으면 자동으로 해당 라이브러리를 로드
- 코덱 풀: 압축기와 해제기를 재사용해서 객체 생성 비용 절감 가능

5.2.2 압축과 입력 스플릿
- 압축 포맷이 분할을 지원하는지 여부를 알고 있는 것은 중요함
- gzip은 분할을 지원하지 않음: 리더가 다음 블록의 시작으로 이동하려면 스트림과 동기화되어 그 스트림의 특정 지점에 있을 수 있는 어떤 방법을 지원해야 하는데, DEPLATE 압축 방식은 각 블록의 시작점을 구별할 수 없음
- 이때 맵리듀스는 파일을 분할하여 하지 않으면서 최적의 방식으로 작동 -> 제대로 동작하긴 하지만 지역성 비용 발생, 시간이 더 많이 걸림
- 압축 파일이 LZO라면 -> 같은 문제가 생김, 그러나 색인 도구를 사용해서 LZO 파일을 전처리 가능
<어떤 압축 포맷을 사용해야 하는가?>
- 압축과 분할 모두를 지원하는 컨테이너 파일 포맷을 사용하라
- 분할을 지원하는 압축 포맷을 사용, 또는 분할을 지원하기 위해 색인될 수 있는 포맷을 사용
- 애플리케이션에서 파일을 청크로 분할하고, 지원되는 모든 압축 포맷을 사용하여 각 청크를 개별적으로 압축
- 파일을 압축하지 말고 그냥 저장하라
-> 파일의 크기가 매우 크면 전체 파일에 대한 분할을 지원하지 않는 압축 포맷은 권장하지 않음
5.2.3 맵리듀스에서 압축 사용하기
- 입력 파일 압축 -> 맵리듀스는 파일 확장명을 통해 사용할 코덱을 결정, 파일을 읽을 때 자동으로 압축을 해제



<맵 출력 압축>
- 맵 단계에서 임시 출력을 압축 -> 전송한 데이터양을 줄여 성능을 향상시킬 수 있음


위 코드를 추가하면 gzip 맵 출력 압축을 활성화할 수 있음
5.3 직렬화
- 직렬화: 네트워크 전송을 위해 구조화된 객체를 바이트 스트림으로 전환하는 과정
- 역직렬화: 바이트 스트림을 일련의 구조화된 객체로 역전환하는 과정이다
- 하둡 시스템에서 노드 사이의 프로세스 간 통신은 원격 프로시저 호출(RPC)을 사용하여 구현됨
- RPC 직렬화 포맷이 유익한 이유
- 간결성: 데이터 센터에서 가장 희소성이 높은 자원인 네트워크 대역폭 절약 가능
- 고속화: 프로세스 간 통신은 분산 시스템을 위한 백본을 형성, 따라서 직렬화와 역직렬화는 가능하면 오버헤드가 작아야 함
- 확장성: 프로토콜은 새로운 요구사항을 만족시키기 위해 점차 변경되므로 클라이언트와 서버 사이의 통제 방식과 관련된 프로토콜의 발전도 직관적이어야 함
- 상호운용성: 일부 시스템을 위해 다양한 언어로 작성된 클라이언트를 지원하는 편이 좋음
-> RPC 직렬화 포맷의 네 가지 유익한 속성은 영속적인 저장소 포맷을 위해서 중요함
- 하둡은 Writable이라는 매우 간결하고 빠른 자체 직렬화 포맷을 사용. 그러나 확장하거나 자바 외에 다른 언어를 사용하는 것은 어려움
5.3.1 Writable
- Writable 인터페이스는 자신의 상태 정보를 DataOutput 바이너리 스트림으로 쓰기 위한 메서드와 DataInput 바이너리 스트림으로부터 상태 정보를 읽기 위한 메서드를 정의

<WritableComparable과 비교자>
- IntWritable은 단순히 Writable과 java.lang.Comparable 인터페이스의 서브인터페이스인 WritableComparable 인터페이스를 구현
- 맵리듀스에서 타입 비교는 중요: 키를 서로 비교하는 정렬 과정을 수반하기 때문

- WritableComparator는 범용적으로 WritableComparable 클래스의 RawComparator를 구현한 것
- 스트림으로부터 비교할 객체를 역직렬화, 객체의 compare() 메서드를 호출해주는 원시 compare() 메서드의 기본 구현체를 제공
- RawComparator 인스턴스를 만드는 팩토리처럼 동작
5.3.2 Writable 클래스

<자바 기본 자료형을 위한 Writable 래퍼>
- char를 제외한 모든 자바 기본 자료형을 위한 Writable 래퍼가 존재

- 정수를 인코딩할 때 고정길이 포맷과 가변길이 포맷을 선택할 수 있음
- 가변길이 포맷: 인코딩할 때 그 값이 충분히 작다면 단일 바이트만 사용, 값이 크다면 첫 번째 바이트를 사용하여 그 값이 양수인지 음수인지 그리고 얼마나 많은 바이트가 뒤에서 사용되는 지 표시함
- 고정길이와 가변길이 인코딩을 선택하는 기준은?
- 고정길이: 전체 공간에서 값이 매우 균일하게 분포되어 있을 때 적합
<텍스트>
- Text는 UTF-8 시퀀스를 위한 Writable 구현체
- 문자열 인코딩에 다수의 바이트를 저장하기 위해 가변길이 인코딩으로 int를 사용 = 최댓값은 2GB
<인덱스 만들기>
- Text 클래스에서 인덱스는 인코딩된 바이트 시퀀스의 위치 관점

<유니코드>
- 한 바이트 이상을 인코딩하는 문자를 사용해보면 text와 String의 차이점을 명확히 알 수 있음

<반복>
- Text에서 유니코드 문자를 반복할 때는 인덱스를 위해 바이트 오프셋을 사용해야 하므로 매우 복잡

<가변성>
- String과의 다른 차이점은 Text는 가변적이라는 것이다

<스트링으로 변환>
- toString() 메서드를 이용해서 Text 객체를 String으로 변환
<BytesWritable>
- BytesWritable은 바이너리 데이터의 배열에 대한 일종의 래퍼
- BytesWritable은 가변적이고 그 값은 set() 메서드를 호출해서 변경 가능
<NullWritable>
- NullWritable은 Writable의 특별한 유형 중 하나로 길이가 0인 직렬화를 가짐
- 이 인스턴스는 NullWritable.get()을 호출하여 얻을 수 있음
<ObjectWritable과 GenericWritable>
- ObjectWritable: 자바 기본 자료형, 또는 이러한 자료형의 배열을 위한 범용 래퍼
- GenericWritable: 자료형의 수가 적고 미리 알려진 경우에는 정적 자료형 배열과 그 자료형에 대한 직렬화된 참조인 인덱스를 사용하여 공간 낭비를 줄일 수 있음
<Writable 컬렉션>



- 일반적인 집합은 NullWritable 값과 함께 MapWritable 을 사용하여 흉내 낼 수 있다
- MapWritable의 아이디어를 차용하여 일반적인 ListWritable을 작성하는 대안도 있다
5.3.3 커스텀 Writable 구현하기
- 하둡은 대부분의 목적을 만족시킬 수 있는 유용한 Writable 구현체를 제공하지만, 가끔 커스텀 구현체를 직접 작성할 필요도 있음
- 바이너리 표현과 정렬 순서에 대한 안전한 통제 가능


- 모든 Writable 구현체는 맵리듀스 프레임워크가 인스턴스화하고 readFields()를 호출하여 그 필드를 채울 수 있는 기본 생성자를 가져야 함
- TextPair의 write() 메서드는 각 Text 객체에 출력을 위임하는 방식으로 각 Text 객체를 출력 스트림에 순차적으로 직렬화함
- 어떠한 값 객체를 자바로 작성할 때와 마찬가지로 java.lang.Object의 hashcode(), equals(), toString() 메서드도 반드시 재정의해야 함
- TextPair는 WritableComparable의 구현체임
<성능 향상을 위해 RawComparator 구현하기>
- TextPair는 두 Text 객체를 합친 것
- 초기의 길이를 읽고 첫 번째 Text 객체의 바이트 표현이 얼마나 긴지 알아내기
- Text의 TawComparator에 위임하고 적절한 오프셋을 넘겨주어 호출

- 각 바이트 스트림에 첫 번째 Text 필드의 길이에 해단하는 firstL1과 firstL2를 계산
- 정적 블록에 해당 원시 비교자를 등록
<커스텀 비교자>
- RawComparator로 작성하는 것이 좋음
- RawComparator: 기본 비교자에서 정의한 자연 정렬 순서와는 다른 정렬 순서를 구현한 비교자


<직렬화 프레임워크>
- Serialization의 구현체로 표현됨
- Serialization은 Serializer 인스턴스와 Desrializer 인스턴스로 매핑하는 방법의 정의
- Serialization 구현페는 io.Serializations 속성에 클래스 이름의 목록을 콤마로 분리하여 설정하여 등록
- 하둡은 자바 객체 직렬화를 사용하는 JavaSerialization이라는 클래스를 포함함
<왜 자바 객체 직렬화를 사용하지 않는가?>
- 직렬화는 하둡의 핵심이기 때문에 객체를 정확하게 쓰고 읽을 수 있는 방법에 대한 정교한 제어 능력 필요
- 프로세스 상호 간 통신은 하둡에서 매우 중요함
- 자바 직렬화의 문제는 간결성, 고속화, 확장성, 상호운용성과 같은 직렬화 포맷에 대한 표준을 만족시키지 않는다는 것
<직렬화 IDL>
- IDL을 사용하여 언어 중립적이고 선언적 방식으로 타입을 정의: 상호운용성이 매우 좋다
5.4 파일 기반 데이터 구조
- 어떤 애플리케이션에서 데이터를 얻기 위해서는 특별한 데이터 구조가 필요
- 하둡은 다양한 고수준 컨테이너를 개발함
5.4.1 SequenceFile
- 각 로그 레코드는 한 행의 텍스트
- 바이너리 형태로 로그를 남기고 싶다면 일반 텍스트 포맷은 적합X
- SequenceFile은 작은 파일을 위한 컨테이너로도 잘 작동함
<SequenceFile 만들기>
- SequenceFile.Writer 인스턴스를 반환하는 createWriter() 정적 메서드 중 하나를 사용
- append() 메서드로 키-값 쌍을 쓰기
- 쓰기가 끝나면 close() 메서드 호출하기


<SequenceFile 읽기>
- SequenceFile.Reader의 인스턴스 생성
- next() 메서드 중 하나를 반복 호출하여 레코드를 하나씩 읽기


- 순차 파일에서 동기화 포인트의 위치를 보여줌
- 동기화 포인트: 리더가 해당 스트림에서 임의의 위치를 탐색한 후 자신의 위치를 잃어버렸을 때 레코드의 경계를 재동기화 하는 데 사용될 수 있는 스트림의 한 지점
- 순차 파일에서 지정된 위치를 탐색하는 방법
- 파일의 지정된 위치에 리더를 위치시키는 seek() 메서드
- 동기화 포인트 사용하기
<명령행 인터페이스로 SequenceFile 출력하기>
- - text 옵션: 파일의 타입을 검출하고 매직넘버를 조사
- hadoop fs 명령은 순차 파일의 키와 값이 의미 있는 문자열일 때만 제대로 작동함
<SequenceFile 정렬하고 병합하기>
- 맵리듀스 사용하기: 병렬성을 타고났으며 출력 파티션 수를 결정하는 리듀서 수를 지정할 수 있음
<SequenceFile 포맷>
- 순차 파일은 단일 헤더와 하나 이상의 레코드로 구성되어 있음
- 헤더: 키와 값 클래스의 이름, 압축 세부사항, 사용자 정의 메타데이터, 동기화 표시자가 포함된 여러 필드가 있음

-> 레코드의 내부 포맷은 압축이 가능하지 여부에 따라 다름
-> 만일 압축할 수 있다면 그것이 레코드 압축인지 블록 압축인지에 따라서도 차이가 남
- 비압축: 각 레코드는 레코드 길이, 키 길이, 키와 그 값으로 이루어짐
- 레코드 압축에서 키는 압축되지 않음
- 블록 압축: 다수의 레코드를 한번에 압축 -> 압축 밀도가 높다
5.4.2 MapFile
- 키를 기준으로 검색을 지원하는 색인을 포함한 정렬된 SequenceFile
- 색인 자체도 일종의 SequenceFile임
- MapFile은 정렬된 키 순으로 된 맵 항목을 포함한 별도의 SequenceFile을 이용한 색인을 메모리에 로드하는 방식을 사용
- 중요한 사항: 매 항목이 순서에 따라 반드시 추가되어야 함
<MapFile의 변형>
- SetFile: Writable 키의 집합을 저장
- ArrayFile: 키는 배열에서 각 항목의 인덱스를 표현하는 정수 / 그 값은 Writable 값인 MapFile
- BloomMapFile: 빠른 get() 메서드를 지원하는 MapFile
5.4.3 기타 파일 포맷과 컬럼 기반 파일 포맷
- 에이브로 데이터 파일: 대규모 데이터 처리를 위해 설계된 시퀀스 파일과 비슷, 이기종 프로그래밍 언어에도 이식할 수 있음
- 행 기반 파일 포맷: 각 행의 값은 파일에서 연속된 위치에 저장되어 있음

- 컬럼 기반 구조는 접근할 필요가 없는 컬럼은 그냥 건너뛸 수 있음
- 컬럼 기반 저장소에서는 파일의 오직 두 부분만 메모리에 로드됨
- 컬럼 기반 포맷은 읽거나 쓸 때 더 많은 메모리 필요: 메모리에 있는 데이터를 각 행으로 분리하는 버퍼가 추가로 필요하기 때문
- RCFile: 하둡에서 최초로 도임한 컬럼 기반 파일 포맷
'Data > Hadoop' 카테고리의 다른 글
| [하둡, 하이브로 시작하기] 1. 빅데이터 (0) | 2024.05.26 |
|---|---|
| [하둡 완벽 가이드] Chapter 6 맵리듀스 프로그래밍 (0) | 2024.05.08 |
| [하둡] 하둡 설치하기 (0) | 2024.04.07 |
| [하둡 완벽 가이드] Chapter 3 하둡 분산 파일 시스템 (0) | 2024.03.24 |
| [하둡 완벽 가이드] Chapter 2 맵리듀스 (0) | 2024.03.17 |

