분산 파일 시스템: 네트워크로 연결된 여러 머신의 스토리지를 관리하는 파일 시스템 (하둡 - HDFS)
- 네트워크 기반 ➡️ 네트워크 프로그램의 복잡성 소유
3.1 HDFS
HDFS의 설계 특성
- 매우 큰 파일: 수백 메가바이트 ~ 페타바이트
- 스트리밍 방식의 데이터 접근: 전체 데이터셋을 모두 읽을 떄 걸리는 시간 중시
- 범용 하드웨어: 장애가 발생하더라도 사용자가 모르게 작업 수행
HDFS와 잘 맞지 않는 응용 분야
- 빠른 데이터 응답 시간(↔️스트리밍 방식의 데이터 접근): 대안 - HBase
- 수많은 작은 파일(↔️매우 큰 파일): 많은 파일은 하드웨어 용량을 넘어섬
- 다중 라이터와 파일의 임의수정: 파일에서 임의 위치에 있는 내용을 수정하는 것은 허용하지 않음
3.2 HDFS 개념
3.2.1 블록
블록 크기 = 디스크가 한 번에 읽고 쓸 수 있는 데이터의 최대량
(파일시스템 블록의 크기 = 수 킬로바이트, 디스크 블록의 크기 = 512 Byte)
HDFS의 블록 크기 = 128MB(탐색 비용을 최소화하기 위해 용량 ⬆️, 데이터 전송할 때 더 많은 시간 할애)
HDFS 파일 ➡️ 특정 블록 크기의 청크로 쪼개짐 ➡️ 각 청크는 독립적으로 저장
블록 추상화 개념을 도입하면서 얻게 된 이득
- 파일 하나의 크기 > 단일 디스크의 용량: 하나의 파일을 구성하는 여러개의 블록 어떤 디스크에도 저장 가능
- 스토리지 서브시스템 단순화: 블록은 고정 크기, 저장에 필요한 디스크 용량만 계산하면 됨, 메타데이터와 블록 분리
- 복제 구현 적합: 각 블록 - 물리적으로 분리된 다수(3개)의 머신에 복제
#파일 시스템에 있는 각 파일을 구성하는 블록의 목록 노출
% hdsf fsck / -files -blocks
3.2.2 네임노드와 데이터노드
HDFS 클러스터: 네임노드(마스터인 한 개) + 데이터노드(워커인 다수) ➡️ 마스터-워커 패턴으로 동작
- 네임노드: 파일시스템의 네임스페이스 관리, 파일시스템 트리 & 트리에 포함된 모든 파일과 디렉터리에 대한 메타데이터 유지 ➡️ 네임스페이스 이미지 + 에디트 로그 (로컬 디스크에 영속적으로 저장, 블록의 위치 정보 제외)
↕️ HDFS 클라이언크: 네임노드 - 데이터노드 사이에서 통신, 파일시스템 접근
- 데이터노드: 클라이언트 or 네임노드의 요청 ➡️ 블록 저장 & 탐색, 저장하고 있는 블록의 목록 주기적으로 네임노드에 보고
if 네임노드 장애 ➡️ 파일 시스템 정보 탐색 불가능
❗장애복구 기능1: 파일시스템의 메타데이터를 지속적인 상태로 보존하기 위해 파일로 백업
로컬 디스크, 원격의 NFS 마운트 두 곳에 동시에 백업
❗ 장애복구 기능2: 보조 네임노드 운영
보조 네임노드: 주기적으로 네임스페이스 이미지 + 에디트 로그 ➡️ 새로운 네임스페이스 이미지 생성 ➡️ 에디트 로그 크기 조절(충분한 CPU & 네임노드와 비슷한 용량의 메모리 필요 ➡️ 별도의 물리 머신에서 실행), 네임스페이스 이미지의 복제본 보관 ➡️ 주 네임노드 장애 발생 대비
3.2.3 블록 캐싱
데이터노드: 빈번하게 접근하는 블록 파일 ➡️ 오프-힙 블록 캐시(데이터노드의 메모리)에 명시적으로 캐싱 ➡️ 읽기 성능 ⬆️(캐시 풀 + 캐시 지지자 ➡️ 특정 파일 캐싱 명령 가능)
3.2.4 HDFS 패더레이션
HDFS 패더레이션 ➡️ 네임노드가 파일시스템의 네임스페이스 일부를 나누어 관리하는 방식으로 새로운 네임노드 추가 ➡️ 네임노드의 확장성 문제 해결
각 네임노드: 네임스페이스 볼륨(네임스페이스의 메타데이터 구성, 서로 독립 ➡️ 각 네임노드 통신 필요 ❌) + 블록 풀(네임스페이스에 포함된 파일의 전체 블록을 보관, 서로 연결) 관리
3.2.5 HDFS 고가용성
네임노드 메타데이터 다수의 파일 시스템 복제 + 보조 네임노드 ➡️ 데이터 손실 방지
but, 네임노드: 단일 고장점 ➡️ 파일 시스템의 고가용성 궁극적 보장 ❌, 새로운 네임노드가 투입될 때까지 하둡 시스템 전체 먹통
네임노드 장애 복구 방법
파일시스템 메타데이터 복제본을 가진 새로운 네임노드 구동 ➡️ 모든 데이터노드 & 클라이언트에 새로운 네임노드 사용 고지
but, 새로운 네임노드: 네임스페이스 이미지 메모리 로드 ➡️ 에디트 로그 갱신 ➡️ 전체 데이터노드에서 충분한 블록 리포트 받아 안전모드 탈출
동안 어떤 요청도 처리 ❌
❗ 해결방안: 하둡 2.x 릴리즈부터 HDFS 고가용성(HA) 지원
활성 네임노드 장애 ➡️ 대시 네임노드가 역할을 이어받음 ➡️ 큰 중단 없이 클라이언트의 요청 처리
장애복구 컨트롤러(객체) : 대기 네임노드 활성화 전환 작업
- 주키퍼 이용 ➡️ 단 하나의 네임노드만 활성 상태에 있는 것을 보장
- 각 네임노드: 경량의 장애복구 컨트롤러 프로세스로 네임노드 장애 감시(하트비트 방식), 장애 발생 ➡️ 장애복구 지시
- 우아한 장애복구: 정기적인 유지관리 ➡️ 관리자가 수동으로 초기화, 네임노드 2개 서로 역할 바꾸기 ➡️ 전환 순서 제어
-❓문제점: 장애가 발생한 네임노드가 현재 실행되지 않고 있다는 확신 ❌
3.3 명령행 인터페이스
3.3.1 기본적인 파일시스템 연산
일반적인 파일 시스템 연산(파일 읽기, 디렉터리 생성, 파일 이동, 데이터 삭제, 디렉터리 목록 출력) 수행
% hadoop fs -copyFromLocal input/docs/quangle.txt \
hdfs://localhost/user/tom/quangle.txt
#하둡 시스템의 쉘 명령어 fs 호출% hadoop fs -copyFromLocal input/docs/quangle.txt /user/tom/quangle.txt
#상대 경로를 사용하여 HDFS의 홈 디렉터리로 파일 복사
#HDFS의 홈 디렉터리: /user/tom% hadoop fs -mkdir books
% hadoop fs -ls .
#출력 결과
#첫 번째 열 - 파일의 모드
#두 번째 열 - 파일의 복제 계수
#세 번째 & 네 번째 - 파일의 소유자 & 그룹
#다섯 번째 - 바이트 단위의 파일 크기(디렉터리: 0)
#여섯 번째 & 일곱 번째 - 마지막으로 수정된 날짜 & 시간
#여덟 번째 - 파일 or 디렉터리의 절대 경로로 표시된 이름HDFS
읽기 권한(r), 쓰기 권한(w), 실행 권한(x) 존재
파일의 실행 지원 ❌ ➡️ 파일에 대한 실행 권한 무시, but 디렉터리에 대한 실행 권한: 하위 디렉터리의 접근 위해 필요
각 파일 & 디렉터리: 소유자, 그룹, 모드(소유자, 그룹 멤버, 그 밖의 사용자)
3.4 하둡 파일시스템
자바 추상 클래스(org.appache.hadoop.fs.FileSystem): 하둡의 파일시스템을 접근할 수 있는 클라이언트 인터페이스
| 파일 시스템 | URI 스킴 | 자바 구현체(org.apache.hadoop 아래) | 설명 |
| Local | file | fs.LocalFileSystem | 클라이언트 측의 체크섬 사용하는 로컬 디스크를 위한 파일시스템. if 로컬 파일 시스템 체크섬 사용 ❌: RawLocalFileSystem 사용 |
| HDFS | hdfs | hdfs.DistributedFileSystem | 하둡 분산 파일 시스템. HDFS: 맵리듀스와 효율적으로 연동하기 위해 설계 |
| WebHDFS | webhdfs | hdfs.web.WebHdfsFileSystem | HTTP를 통해 HDFS에 인증을 통한 읽기/쓰기 제공 파일시스템 |
| Secure WebHDFS |
swebhdfs | hdfs.web.SWebHdfsFileSystem | WebHDFS의 HTTPS 버전 |
| HAR | har | fs.HarFileSystem | 아카이브 파일을 위한 파일 시스템 하둡 아카이브: 네임노드의 메모리 용량을 줄이기 위해 HDFS에 수많은 파일을 묶어놓은 파일 hadoop archive 명령어 실행 ➡️ HAR 파일 생성 |
| View | viewfs | viewfs.ViewFileSystem | 다른 하둡 파일시스템을 위한 클라이언트 측 마운트 테이블 페더레이션 네임노드의 마운트 지점을 생성할 때 주로 사용 |
| FTP | ftp | fs.ftp.FTPFileSystem | FTP 서버를 지원하는 파일시스템 |
| S3 | s3a | fd.s3a.S3AFileSystem | 아마존 S3를 지원하는 파일시스템 구 버전의 s3n(S3 네이티브) 구현체 대체 |
| Azure | wasb | fs.azure.NativeAzureFileSystem | 마이크로소프트의 애저(Azure)를 지원하는 파일시스템 |
| Swift | swift | fs.swift.snative.SwiftNativeFileSystem | 오픈스택 스위프트(Swift)를 지원하는 파일시스템 |
% hadoop fs -ls file:///
#로컬 파일시스템의 루트 디렉터리의 파일 목록
3.4.1 인터페이스
HTTP: HTTP REST API 사용
1) 클라이언트의 HTTP 요청 HDFS 데몬이 직접 처리
- 네임노드 & 데이터노트에 내장된 웹 서버가 WebHDFS의 말단으로 작용
- WebHDFS의 활성화 여부: dfs.webhdfs.enabled 속성에 정의(기본값: true)
- 네임노드: 파일에 대한 메타데이터 연산 처리, 파일 데이터를 스트리밍할 데이터노드를 알려주는 HTTP 리다이렉트를 클라이언트에 전송
2) 클라이언트 대신 DistributedFileSystem API로HDFS에 접근하는 프록시 경유
- 하나 또는 그 이상의 독립 프록시 서버 통함 ➡️ 클라이언트: 네임노드 & 데이터노드 직접 접근 필요 ❌
- 프록시 서버: 상태 저장 필요 ❌, 표준 로드 밸런서 사용 가능

C
- libhdfs: HDFS에 접근하기 위해 작성한 C 라이브러리, 모든 하둡 파일시스템에 접근 가능
- 자바 네이티브 인터페이스(JNI) 사용
NFS
- NFSv3 게이트웨이 이용 ➡️ 로컬 클라이언트 파일시스템에 HDFS 마운트 가능, Unix 유틸리티 & POSIX 라이브러리 (파일 업로드 및 일반적인 프로그래밍 언어에서 파일시스템 다룸) 사용 가능
FUSE: Filesystem in Userspace(사용자 공간에서의 파일시스템), 사용자 공간 &유닉스 파일시스템 통합 파일시스템 지원
- Fuse-DFS contrib 모듈: 표준 로컬 파일시스템에 HDFS 마운트 기능 제공
- Fuse-DFS: C로 작성된 libhdfs로 HDFS 인터페이스 구현
3.5 자바 인터페이스
3.5.1 하둡 URL로 데이터 읽기
InputStream in = null;
try {
in = new URL("hdfs://host/path").openStream();
//in을 처리한다.
} finally {
IOUtils.closeStream(in);
}
FsUrlStramHandlerFactory의 인스턴스와 함께 URL 클래스의 setURLStramHandlerFactory() 메서드 호출해 수행
JVM 하나당 한 번씩만 호출 가능 ➡️ 정적 블록에서 실행
❓ 한계: 프로그램의 일부 다른 부분에서 URLStramHandlerFactory 설정 ➡️ 하둡 URL로부터 데이터를 읽을 수 없음
❗ 대안: 3.5.2 파일시스템 API로 데이터 읽기
//하둡 파일시스템의 파일을 URLStreamHandler를 사용하여 표준 출력으로 보여주기
public class URLCat {
static {
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args) throws Exception {
InputStream in = null;
try {
in = new URL(args[0]).openStram();
IOUtils.copyBytes(in, System.out, 4096, false);
// IOUtils 클래스: 바이트 복사
// 세 번째 인자: 버퍼 크기, 네 번째 인자: 복사 완료 시 스트림 닫기 여부(System.out - 닫을 필요 X)
} finally {
IOUtils.closeStram(in);
}
}
}
3.5.2 파일시스템 API로 데이터 읽기
애플리케이션에서 URLStramHandlerFactory 설정 불가능 ➡️ FileSystem API 사용 ➡️ 파일에 대한 입력 스트림 열기
하둡 파일시스템의 파일: 하둡 Path(하둡 파일시스템 URL) 객체로 표현
FileSystem: 일반적인 파일시스템 API, 접근할 파일시스템(HDFS)에 대한 인스턴스 필요
//FileSystem 인스턴스를 얻을 수 있는 정적 팩토리 메서드
public static FileSystem get(Configuration conf) throws IOException
// Configuration 객체: 클라이언트/서버의 환경 설정 포함
public static FileSystem get(URL uri, Configuration conf) throws IOException
public static FileSystem get(URL uri, Configuration con, String user) throws IOException
// 첫 번째 메서드: 기본 파일시스템 반환
// 두 번째 메서드: 주어진 URI 스킴 & 권한으로 파일 시스템 결정(URI에 스킴 명시 X: 기본 파일시스템으로 간주)
// 세 번째 메서드: 특정 사용자를 명시하여 파일시스템 추출public static LocalFileSystem getLocal(Configuration conf) throws IOException
//FileSystem 인스턴스를 얻으면 open() 메서드를 호출해 파일에 대한 입력 스트림 열 수 있음public FSDataInputStream open(Path f) throws IOException
public abstract FSDataInputStream open(Paht f, int bufferSize) throws IOException
// 첫 번째 메서드: 기본 버퍼 크기(4KB) 사용
//FileSystem API를 직접 사용하여 하둡 파일시스템의 파일을 표준 출력으로 보여주기
public class FileSystemcat {
public static void main(String[] args) throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}//FileSystem의 open() 메서드: FSDataInputStream 클래스 반환
package org.apache.hadoop.fs;
public class FSDataInputStream extends DataInputStream
implements Seekable, PositionedReadable {
// Seekable 인터페이스: 파일에서 특정 위치로 이동하는 것을 허용
// 코드 생략
}public interface Seekable {
void seek(long pos) throws IOException;
long getPos() throws IOException;
}//seek를 사용해서 하둡 파일시스템의 파일을 표준 출력으로 두 번 보여주기
public class FileSystemDoubleCat {
public static void main(String[] args) throws Exception {
Stirng uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
FSDataInputStream in = null
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 4096, false);
in.seek(0); //파일의 처음으로 돌아간다
IOUtils.copyBytes(in, System.out, 4096, false);
} finally {
IOUtils.closeStream(in);
}
}
}// FSDataInputStream: 오프셋에서 파일의 일부를 읽기 위한 PositionedReadable 인터페이스 제공
public interface PositionedReadable {
public int read(long position, byte[] buffer, int offset, int length)
// read() 메서드: 파일의 주어진 position에서 length만큼의 바이트를 읽어서 buffer의 주어진 offset에 그 내용 복사
// 반환값: 실제로 읽은 바이트 크기
// 호출자: 반환값 < length 반드시 확인
throws IOException;
public void readFully(long position, byte[] buffer, int offset, int length)
throws IOException;
public void readFully(long position, byte[] buffer) throws IOException;
}
3.5.3 데이터 쓰기
public FSDataOutputStream create(Path f) throws IOException
// 생성할 파일을 Path 객체로 받아서 출력 스트림으로 씀
// create() 메서드: 오버로드 버전(기존 파일을 강제로 덮어쓰기, 파일의 복제 계수, 파일 쓰기의 버퍼 크기, 파일의 블록 크기, 파일의 권한 명시) 허용
// create() 메서드: 부모 디렉터리가 없으면 자동으로 생성, exists() 메서드 호출로 부모 디렉터리 유무 확인package org.apache.hadoop util;
public interface Progressable {
public void progress();
}
// Progressable: 오버로드 메서드, 콜백 인터페이스 넘겨줌public FSDataOutputStream append(Path f) throws IOException?
//append() 메서드로 기존 파일에 데이터 추가// 로컬 파일을 하둡 파일시스템으로 복사하기
public class FileCopyWithProgress {
public static void main(String[] args) throws Exception {
String localSrc = args[0];
String dst = args[1];
InputStream in = inew BufferedInputStream(new FileInputStream(localSrc));
Configuration conf - new Configuration();
FileSystem fs = FileSystem.get(URI.create(dst), conf);
OutputStream out = fs.create(new Path(dst), new Progressable() {
public void progress() {
System.out.print(".");
}
});
IOUtils.copuBytes(in, out, 4096, true);
}
}// FileSystem 클래스의 create() 메서드: FSDataOutputStream 반환, 파일에서 현재 위치를 얻기 위한 메서드 지원
package org.apache.hadoop.fs;
public class FSDataOutputStream extends DataOutputStream implements Syncable {
public long getPos() throws IOException {
// 코드 생략
}
//코드 생략
}
//FSDataOutputStream: 파일 탐색(Seek 기능) 지원 X
3.5.4 디렉터리
public boolean mkdirs(Path f) throws IOException
//FileSystem: 디렉터리를 생성하기 위한 메서드 제공
// 존재하지 않는 모든 부모 디렉터리 생성
3.5.5 파일시스템 질의
FileStatus 클래스: 파일 & 디렉터리 메타데이터(파일 길이, 블록 크기, 복제, 수정 시간, 소유권, 권한 정보) 포함
public class ShowFileStatusTest {
private MiniDFSCluster cluster; //현재 운영되고 있는 HDFS 클러스터를 테스트하기 위해 사용
private FileSystem fs;
@Before
public void setUp() throws IOException {
Configuration conf = new Configuration();
if (System.getProperty("test.build.data") == null {
System.setProperty("test.build.data", "/tmp");
}
cluster = new MiniDFSCluster.Builder(conf).build();
fs = cluster.getFileSystem();
Outputstream out = fs.create(new Path("/dir/file"));
out.write("content".getBytes("UTF-8"));
out.close();
}
@After
public void tearDown() throws IOException {
if (fs != null) { fs.close(); }
if (cluster != null) { cluster.shutdown(); }
}
@Test(expected = FileNotFoundException.class)
public void throwsFileNotFoundExceptionFile() throws IOException {
fs.getFileStatus(new Path("no-such-file"));
}
@Test
public void fileStatusForFile() throws IOException {
Path file = new Path("/dir/file");
FileStatus stat = fs.getFileStatus(file);
assertThat(stat.getPath().toUri().getPath(), is("/dir/file"));
assertThat(stat.isDirectory(), is(false));
assertThat(stat.getLen(), is(7L));
assertThat(stat.getModificationTime(), is(lessThanOrEqualTo(System.currentTimeMillis())));
assertThat(stat.getReplication(), is((short) 1));
assertThat(stat.getBlockSize(), is(128 * 1024 * 1024L));
assertThat(stat.getOwner(), is(System.getProperty("user.name")));
assertThat(stat.getGroup(), is("supergroup"));
assertThat(stat.getPermission().toString(), is("rw-r--r--"));
}
@Test
public void fileStatusForDirectory() throws IOException {
Path dir = new Path("/dir");
FileStatus stat = fs.getFileStatus(dir);
assertThat(stat.getPath().toUri().getPath(), is("/dir"));
assertThat(stat.isDirectory(), is(true));
assertThat(stat.getLen(), is(0L));
assertThat(stat.getModificationTime(), is(lessThanOrEqualTo(System.currentTimeMillis())));
assertThat(stat.getReplication(), is((short) 0));
assertThat(stat.getBlockSize(), is(0L));
assertThat(stat.getOwner(), is(System.getProperty("user.name")));
assertThat(stat.getGroup(), is("supergroup"));
assertThat(stat.getPermission().toString(), is("rwxr-xr-x"));
// 파일 or 디렉터리가 없으면: FileNotFoundException
// 파일 or 디렉터리 존재여부: FileSystem의 exists() 메서드 호출
public boolean exists(Path f) throws IOExceptionpublic Filestatus[] listStatus(Path f) throws IOException
public Filestatus[] listStatus(Path f, PathFilter filter) throws IOException
public Filestatus[] listStatus(Path[] files) throws IOException
public Filestatus[] listStatus(Path[] files, PathFilter filter) throws IOException
// FileSystem의 listStatus() 메서드: 특정 디렉터리의 내용 조회//하둡 파일시스템의 경로 집합에 대한 파일 상태 보기
public class ListStatus {
public static void main(String[] args throws Exception {
String uri = args[0];
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri), conf);
Path[] paths = enw Path[args.length];
for(int i = 0; i < paths.length; i++) {
paths[i] = new Path(args[i]);
}
FileStatus[] status = fs.listStatus(paths);
Path[] listedPaths = FileUtil.stat2Paths(status);
for (Paht p : listedPaths) {
System.out.println(p);
}
}
}// 글로빙: 모든 파일과 디렉터리를 단일 표현식으로 와일드카드 문자를 이용하여 다중 파일을 매칭
// 하둡에서 지원하는 두 개의 FileSystem 메서드
public FileStatus[] globStatus(Path pathPattern) throws IOException
public FileStatus[] globstatus(Path pathPattern, PathFilter filter) throws IOException
// globstatus() 메서드: 주어진 패턴에 매칭되는 경로에 대한 FileStatus 객체의 배열을 경로를 기준으로 정렬하여 반환| 글로브 | 이름 | 일치되는 대상 |
| * | 별표 | 0개 이상의 문자 |
| ? | 물음표 | 단일 문자 |
| [ab] | 문자 집합 | 집합 {a, b}에 있는 단일 문자 |
| [^ab] | 부정된 문자 집합 | 집합 {a, b}에 없는 단일 문자 |
| [a - b] | 문자 영역 | (닫힌) 영역 [a, b]에 있는 단일 문자 (사전적으로는 a <= b) |
| [^a - b] | 부정된 문자 영역 | (닫힌) 영역 [a, b]에 없는 단일 문자 (사전적으로는 a <= b) |
| {a, b} | 양자택일 | 표현 a 또는 b에 일치 |
| \c | 이스케이프 문자 | 문자 c가 메타문자일 때 문자 c와 일치 |
// FileSystem의 listStatus() & globStatus() 메서드: 프로그래밍 방식으로 매칭을 허용하는 PathFilter를 옵션으로 지원
package org.apache.hadoop.fs;
public interface PathFilter {
boolean accept(Paht path);
}//정규표현식에 매칭되는 특정 경로를 제외하기 위한 PathFilter
public class RegexExcludePathFilter implements PahtFilter {
private final String regex;
public RegexExcludePathFilter(String regex) {
this.regex = regex;
}
public boolean accept(Path path){
return !path.toString().matches(regex);
}
}
//필터: 정규표현식에 매칭되지 않는 파일만 통과
3.5.6 데이터 삭제
// FileSystem의 delete() 메서드: 파일과 디렉터리 영구적으로 삭제
public boolean delete(Path f, boolean recursive) throws IOException
3.6 데이터 흐름
3.6.1 파일 읽기 상세
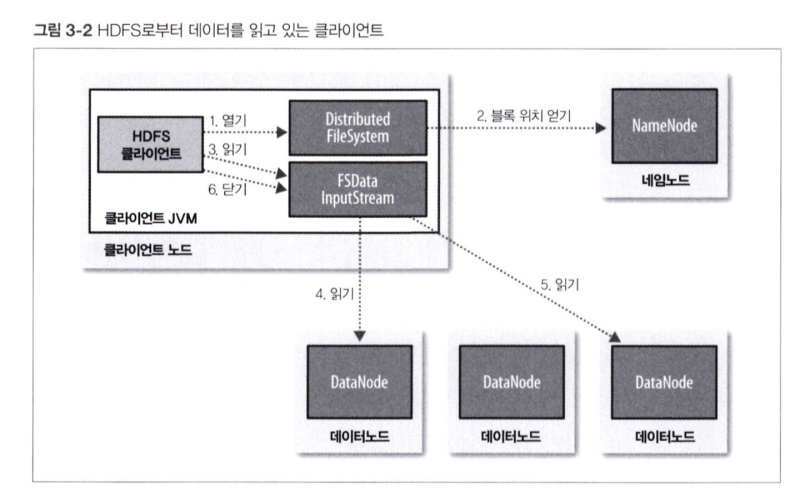
1. 열기
클라이언트: HDFS가 DistributedFileSystem 인스턴스인 FileSystem 객체의 open() 메서드 호출 ➡️ 원하는 파일 열기
2. 블록 위치 얻기
DistributedFileSystem: RPC 사용 ➡️ 네임노드 호출 ➡️ 파일의 첫 번째 블록 위치 파악
3. 읽기
클라이언트: 스트림을 읽기 위해 read() 메서드 호출
4. 읽기
DFSInputStream(파일의 첫 번째 블록의 데이터노드 주소 저장): 가장 가까운 데이터노드와 연결
해당 스트림에 대해 read() 메서드를 반복적으로 호출 ➡️ 데이터노드 ▶️ 클라이언트 (모든 데이터 전송)
5. 읽기
블록의 끝에 도달 ➡️ DFSInputstream: 데이터노드의 연결 닫음, 다음 블록의 데이터노드 찾음
6. 닫기
클라이언트: 스트림 ➡️ 블록을 순서대로 하나씩 읽음, 다음 블록의 데이터노드 위치를 얻기 위해 네임노드 호출
DFSInputStream: 블록마다 데이터노드와 새로운 연결
if 모든 블록에 대한 읽기 끝) 클라이언트: FSDataInputStream의 close() 메서드 호출
3.6.2 파일 쓰기 상세

1. 생성
클라이언트: DistributedFileSystem의 Create() 호출 ➡️ 파일 생성
2. 생성
DistributedFileSystem: 네임노드에 RPC 요청
➡️ 네임노드: 요청한 파일과 동일한 파일 존재 여부, 클라이언트 파일 생성 권한 등 다양한 검사
➡️ if 검사 통과) 네임노드: 새로운 파일의 레코드 생성 / if 검사 통과 ❌) 파일 생성 실패, 클라이언트의 IOException 발생
3. 쓰기
DFSOutputStream: 데이터 패킷으로 분리 ➡️ 내부 큐(데이터 큐)로 패킷 전송 ➡️ DataStreamer: 데이터 큐에 있는 패킷 처리(복제 수준 = 파이프라인의 개수)
4. 패킷 쓰기
첫 번째 데이터노드: 각 패킷 저장 ➡️ 파이프라인의 두 번째 데이터노드로 전송 ➡️ 두 번째 데이터노드: 받은 패킷 저장 ➡️ 파이프라인의 세 번째(마지막) 데이터노드로 전달
5. ack 패킷
DFSOutputStream: 데이터노드의 승인 여부를 기다리는 내부 패킷 큐(ack 큐) 유지
ack 內 패킷: 파이프라인의 모든 데이터노드로부터 ack 응답을 받아야 제거
6. 닫기
클라이언트: 데이터 쓰기를 완료할 때 크트림에 close() 메서드 호출(close(): 데이터노드 파이프라인에 남아있는 모든 패킷 플러시 ➡️ 승인 대기)
7. 완료
모든 패킷 완전히 전송 ➡️ 네임노드에 '파일 완료' 신호 전송
신뢰성 쓰기 대역폭 ↔️ 읽기 대역폭
i.e., 단일 노드에 모든 복제본 배치 ➡️ 중복성 ❌, 대역폭 ⬇️ ➡️ 해당 노드 장애 발생 시 블록의 데이터 유실
i.e., 서로 다른 데이터 센터에 복제본 배치 ➡️ 중복성 최대화, 대역폭 비용 ⬆️
❗ 전략
첫 번째 복제본: 클라이언트와 같은 노드에 배치
두 번째 복제본: 첫 번째 노트와 다른 랙의 노드
세 번째 복제본: 두 번째 노드와 같은 랙, 다른 노드
... n 번째 복제본: 무작위 배치
➡️ 신뢰성(블록을 두 랙에 저장) + 쓰기 대역폭(쓰기: 하나의 네트워크 스위치만 통과) + 읽기 성능(가까운 랙 선택) + 블록 분산(클라이언트: 로컬 랙에 하나의 블록만 저장)
3.6.3 일관성 모델
Path p = new Path("p");
FSDataOutputStream out = fs.create(p);
out.write("content".getBytes("UTF-8"));
out.hflush(); //운영 체제에 플러시
out.getFD().sync(); //디스크에 동기화
assertThat(fs.getFileStatus(p).getLen(), is(((long "content".length())));
//hflush() 메서드: 데이터노트에 있는 모든 버퍼의 내용 플러시 강제
//hsync() 메서드: 강한 신뢰성 보장, fsync() 시스템 호출과 유사
hflush() or hsync() 호출
❌, 클라이언트 or 시스템 장애 발생 ➡️ 데이터 블록 유실
❗ 적절한 시점에 hflush() 반드시 호출
강건성 ↔️ 처리량 ➡️ 적절한 균형 필요
3.7 distcp로 병렬 복사하기
distcp: 병렬로 다량의 데이터를 하둡 파일시스템으로부터 복사하기 위한 프로그램
% hadoop distcp file1 file2
// 파일 복사
% hadoop distcp dir1 dir2
// 디렉터리 복사
//if dir2 존재 X: 새롭게 생성, dir1 안의 파일 복사
//if dir2 존재: dir1은 dir2 하위에 복사(디렉터리 구조: dir2/dir1)
% hadoop distcp -update dir1 dir2
//-update 옵션: 변경이 이루어진 파일들만 복사
3.7.1 HDFS 클러스터 균형 유지
❓ 다른 잡을 위해 일부 노드를 사용, 맵의 수 제한 ➡️ 클러스터 불균형
❗ balancer 도구 사용
'Data > Hadoop' 카테고리의 다른 글
| [하둡 완벽 가이드] Chapter 6 맵리듀스 프로그래밍 (0) | 2024.05.08 |
|---|---|
| [하둡 완벽 가이드] Chapter 4 하둡 I/O (0) | 2024.05.05 |
| [하둡] 하둡 설치하기 (0) | 2024.04.07 |
| [하둡 완벽 가이드] Chapter 2 맵리듀스 (0) | 2024.03.17 |
| [하둡 완벽 가이드] Chapter 1 하둡과의 만남 (0) | 2024.03.17 |


